
Nerova BlogGuides
Evergreen guides explaining AI agents, AI teams, automation, chatbots, implementation patterns, and practical adoption.
Guides Articles
Evergreen guides explaining AI agents, AI teams, automation, chatbots, implementation patterns, and practical adoption.
This archive groups Nerova Blog posts by search intent so readers can move directly into the type of content they need.
Featured AI Agent & Enterprise AI Articles

The Biggest AI Breakthroughs Through History, and Why Each One Mattered
A clear guide to the biggest AI breakthroughs through history, from the perceptron and backpropagation to AlexNet, word embeddings, attention, transformers, diffusion models, RLHF,
AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What Actually Belongs Where
AI, machine learning, deep learning, and neural networks are related, but they are not the same thing. This practical guide shows how the stack fits together, why transformers...

How ChatGPT-Like Models Actually Work: A Practical Guide From Tokens to Tool Use
A practical guide to how ChatGPT-like models actually work: tokens, embeddings, transformer layers, attention, next-token prediction, pretraining, fine-tuning, RLHF, tools, memory,

Activation Steering, Explained: How Steering Vectors Shift LLM Behavior Without Retraining
Activation steering gives teams a way to nudge model behavior at inference time by editing internal activations instead of retraining weights. This guide explains steering...

What Are Hallucination Neurons in LLMs? A Practical Guide to H-Neurons and Their Limits
A small neuron subset inside transformer feed-forward blocks may say a lot about when an LLM is about to guess. This guide breaks down the H-Neurons research, the later...
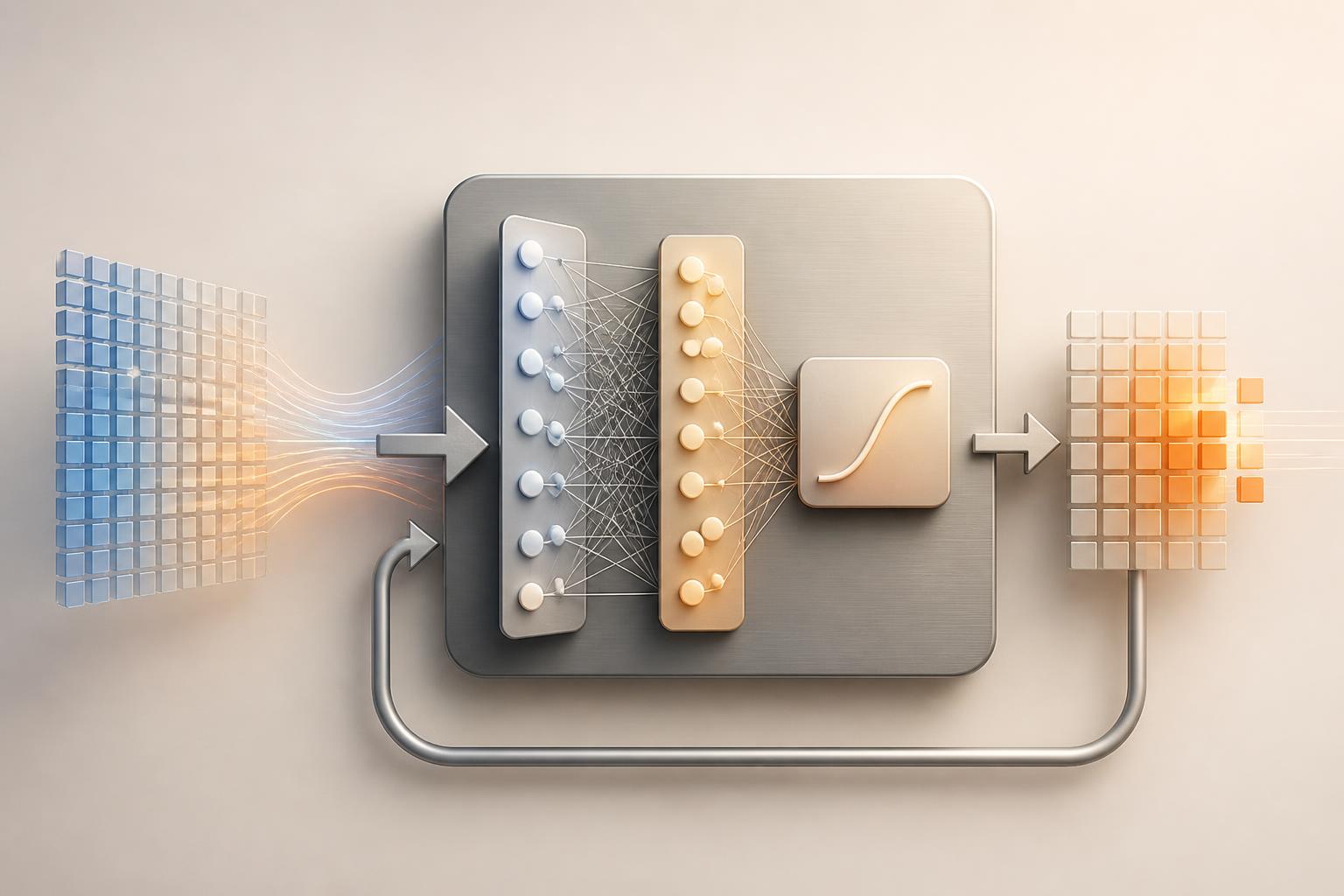
What Feed-Forward Neural Network Layers and MLPs Actually Do
Feed-forward neural network layers still do much of the heavy lifting inside modern models. This guide explains dense layers, matrix multiplication intuition, activations, hidden...

Transformer Architecture From the Inside: How Tokenization, Attention, and Decoding Actually Work
Transformers power modern LLMs, but most explanations stop at “attention.” This guide breaks the model open from input tokens to output logits so technical buyers, operators, and...

How to Train Local AI Models: A Practical Guide for Business Teams
Most companies should not start local model work by launching a giant training run. This guide explains how to choose a base model, decide whether fine-tuning is even necessary...

What Is a Neural Network? A Practical Guide to How It Learns
Learn what neural networks are and how they learn through neurons, weights, activations, layers, loss functions, gradient descent, validation, and overfitting.

What Are Embeddings? A Practical Guide to Dense Vectors, Similarity, and Retrieval
Embeddings turn messy data like text, images, and products into dense vectors that make similarity, retrieval, clustering, and recommendation practical. This guide explains what...

AI Model Evaluation for Machine Learning Teams: A Practical Guide Beyond Accuracy
Learn how machine learning teams should evaluate AI models before and after launch. This practical guide covers train, validation, and test splits, benchmark limits, offline evals,

What Is Backpropagation? A Practical Guide to How Neural Networks Actually Learn
Backpropagation is the calculus that lets neural networks learn, but the useful part is seeing how it behaves inside a real training loop. This guide explains the forward pass...